
Where is this useful?
In many problems, translating into a graph structure can prove helpful, as we can describe our problem in very abstract terms.
Once you’ve translated into this graph structure, often you might want to know whether two vertices are connected via a path, and if this is not the case, what two separate components they come from. Union Find allows us to not only answer this question, but slowly add edges to the graph and still answer these queries fast.
As such, Union Find is useful in any problem where connections are incrementally being added to some structure, and along the way you need to query what vertices are connected.
Implementing the Data Structure
Basics
Let’s first define the interface for our Union Find. We want to provide the ability to merge two vertices, and we should be able to query two vertices, asking if they are connected.
At first, every vertex is disconnected. We can add edges later as need be.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class UnionFind:
"""
vertices are represented as numbers 0->n-1.
"""
def __init__(self, n):
self.n = n
def merge(self, a, b) -> bool:
# Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
pass # TODO
def connected(self, a, b) -> bool:
# Whether the two vertices a and b are connected.
pass # TODO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct UnionFind {
// vertices are represented as numbers 0->n-1.
int n;
UnionFind(int n_verts) : n(n_verts) { }
bool merge(int a, int b) {
// Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
// TODO
}
bool connected(int a, int b) {
// Whether the two vertices a and b are connected.
// TODO
}
};
Now, we can take our first approach at the data structure. Notice that before any merging occurs, each component is uniquely identified by a single vertex contained within. As we merge our vertices, we’ll try keep it that way.
In order to do this, we can model each component as a rooted tree. The root of this tree is the identifier, and so from any vertex in the tree, we can get to the identifier by moving up the tree.
To merge two components (trees), we simply place the second tree as a child of the first tree. The second root no longer identifies a component, and the first root is now the identifier of the combined component.
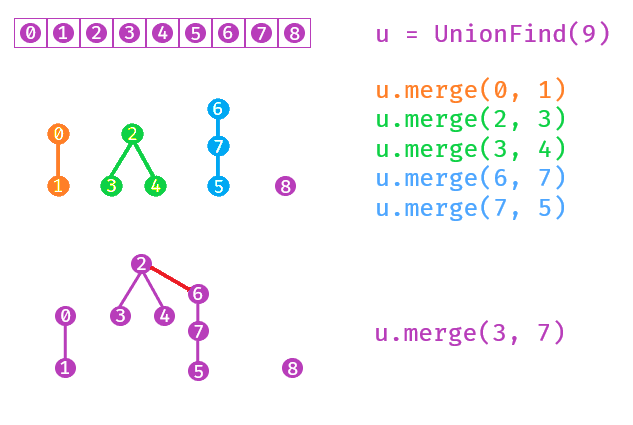
So, to implement this, we’ll create a parent array, which contains the parent of each vertex. For vertices that are the root, they will be their own parents.
We will also need a method to find the identifier of any component, by moving up the tree. We will do this with find in the code.
And we can already get around to implementing connected and merge. For connected, a and b are in the same component if the identifier of their components are the same. For merge, we simply need to modify the parent attribute of one identifier, so that it points to the root of the other component:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class UnionFind:
"""
vertices are represented as numbers 0->n-1.
"""
def __init__(self, n):
self.n = n
# parent[x] = x to begin with.n
self.parent = list(range(n))n
def find(self, a):n
# Find the root of this componentn
if self.parent[a] == a:n
return an
return self.find(self.parent[a])n
def merge(self, a, b) -> bool:
# Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
a = self.find(a)n
b = self.find(b)n
if a == b:n
return Falsen
self.parent[b] = an
return Truen
def connected(self, a, b) -> bool:
# Whether the two vertices a and b are connected.
a = self.find(a)n
b = self.find(b)n
return a == bn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
struct UnionFind {
// vertices are represented as numbers 0->n-1.
int n;
vector<int> parent;n
UnionFind(int n_verts) : n(n_verts), parent(n_verts) {m
iota(parent.begin(), parent.end(), 0);n
}
int find(int a) {n
// Find the root of this componentn
if (parent[a] == a) return a;n
return find(parent[a]);n
}n
bool merge(int a, int b) {
// Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
a = find(a);n
b = find(b);n
if (a == b) return false;n
parent[b] = a;n
return true;n
}
bool connected(int a, int b) {
// Whether the two vertices a and b are connected.
a = find(a);n
b = find(b);n
return a == b;n
}
};
Useful data
A keen eye might’ve spotted that there’s possibility of some bad complexity coming out of these methods. If components are merged badly (So that we have a very unbalanced tree) we can make it so that find (and therefore merge/connected) are O(n) complexity. To improve this, and to make the data structure more useful as a whole, let’s take a quick detour and try to include some other data as part of our data structure:
size: This should be an array which stores the size of each component. Thesizeentry for non-identifier vertices doesn’t matter and can be left with old data.rank: This should be an array which stores the maximum depth of any component tree. Therankentry for non-identifier vertices doesn’t matter and can be left with old data.
It could be a good bit of practice to try this yourself; Modify the methods above to store and update the size and rank values.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
class UnionFind:
"""
vertices are represented as numbers 0->n-1.
"""
def __init__(self, n):
# Number of components
self.n = n
# parent[x] = x to begin with.
self.parent = list(range(n))
# size = number of vertices in componentn
self.size = [1]*nn
# rank = max-depth of component treen
self.rank = [1]*nn
def find(self, a):c
# Find the root of this component
if self.parent[a] == a:
return a
return self.find(self.parent[a])
c
def merge(self, a, b) -> bool:
# Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
a = self.find(a)
b = self.find(b)
if a == b:
return False
self.size[a] += self.size[b]n
self.parent[b] = a
self.rank[a] = max(self.rank[a], self.rank[b])n
if self.rank[a] == self.rank[b]:n
self.rank[a] += 1n
self.n -= 1n
return True
def connected(self, a, b) -> bool:c
# Whether the two vertices a and b are connected.
a = self.find(a)
b = self.find(b)
return a == b
c
def size_component(self, a):n
# Find the size of a particular component.n
# Question: Why do we need to call `find`?n
return self.size[self.find(a)]n
def num_components(self):n
return self.nn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
struct UnionFind {
// vertices are represented as numbers 0->n-1.
int n;
vector<int> parent, size, rank;
UnionFind(int n_verts) : n(n_verts), parent(n_verts), size(n_verts, 1), rank(n_verts, 1) {m
iota(parent.begin(), parent.end(), 0);
}
int find(int a) {c
// Find the root of this component
if (parent[a] == a) return a;
return find(parent[a]);
}c
bool merge(int a, int b) {
// Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
a = find(a);
b = find(b);
if (a == b) return false;
size[a] += size[b];n
parent[b] = a;
rank[a] = max(rank[a], rank[b]);n
if (rank[a] == rank[b]) rank[a]++;n
n--;n
return true;
}
bool connected(int a, int b) {c
// Whether the two vertices a and b are connected.
a = find(a);
b = find(b);
return a == b;
}c
int size_component(int a) {n
// Find the size of a particular component.n
// Question: Why do we need to call `find`?n
return size[find(a)];n
}n
int num_components() { return n; }n
};
If the maximum of rank[a] and rank[b] is equal to rank[b], then the total depth in the tree will be at most rank[b]+1, since we must include the path from a to b, before considering any children of b.
Armed with this information, we can make some better decisions when it comes to merging, and also start compressing the trees.
Depth reduction
Since we get bad complexity when merging trees with large rank as children, let’s always pick the largest rank tree to be the identifier. Then the overall rank of the resultant tree only increases if the rank of the two original trees was the same.
Additionally, every time we call find, we are traversing up our tree. But in this traversal, it is very cheap to simply connect every vertex along the way to the root vertex, using recursion.
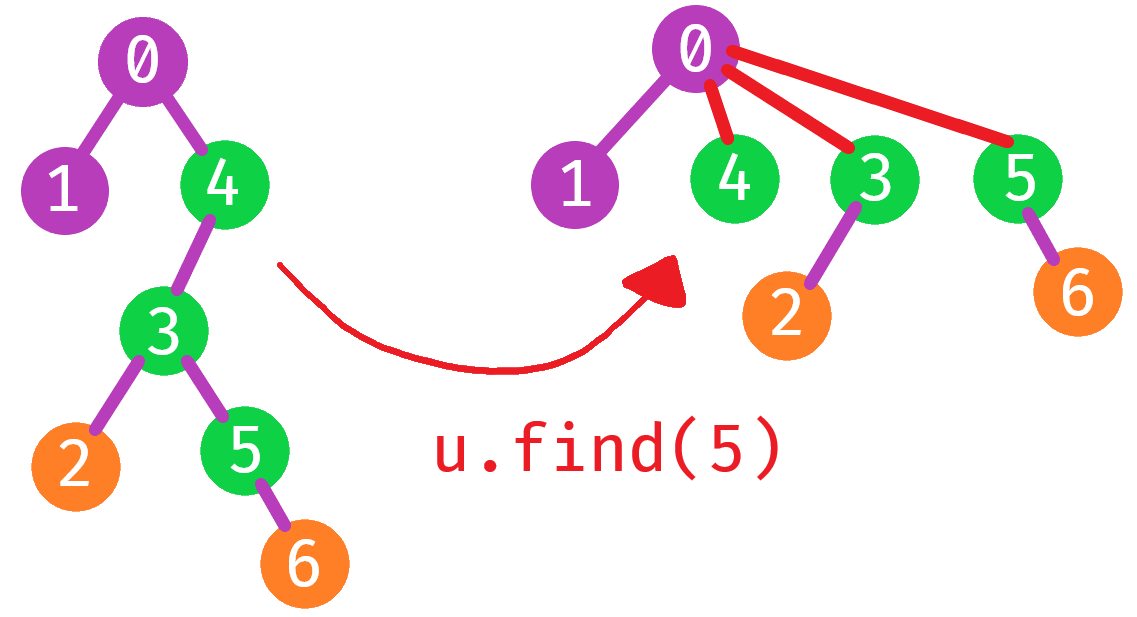
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class UnionFind:
"""
vertices are represented as numbers 0->n-1.
"""
def __init__(self, n):c
# Number of components
self.n = n
# parent[x] = x to begin with.
self.parent = list(range(n))
# size = number of vertices in component
self.size = [1]*n
# rank = max-depth of component tree
self.rank = [1]*n
c
def find(self, a):
# Find the root of this component
if self.parent[a] == a:
return a
# Whenever I call find, set the parent to be right above me.n
b = self.find(self.parent[a])n
self.parent[a] = bn
return bn
def merge(self, a, b) -> bool:
# Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
a = self.find(a)
b = self.find(b)
if a == b:
return False
if (self.rank[a] < self.rank[b]):n
a, b = b, an
self.size[a] += self.size[b]
self.parent[b] = a
if self.rank[a] == self.rank[b]:
self.rank[a] += 1
self.n -= 1
return True
def connected(self, a, b) -> bool:c
# Whether the two vertices a and b are connected.
a = self.find(a)
b = self.find(b)
return a == b
c
def size_component(self, a):c
# Find the size of a particular component.
# Question: Why do we need to call `find`?
return self.size[self.find(a)]
c
def num_components(self):c
return self.n
c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
struct UnionFind {
// vertices are represented as numbers 0->n-1.
int n;
vector<int> parent, size, rank;
UnionFind(int n_verts) : n(n_verts), parent(n_verts), size(n_verts, 1), rank(n_verts, 1) {
iota(parent.begin(), parent.end(), 0);
}
int find(int a) {
// Find the root of this component
if (parent[a] == a) return a;
// Whenever I call find, set the parent to be right above me.n
return parent[a] = find(parent[a]);m
}
bool merge(int a, int b) {
// Merge the two vertices a and b. Return a boolean which is true if they weren't already merged.
a = find(a);
b = find(b);
if (a == b) return false;
if (rank[a] < rank[b]) swap(a, b);n
size[a] += size[b];
parent[b] = a;
if (rank[a] == rank[b]) rank[a]++;
n--;
return true;
}
bool connected(int a, int b) {c
// Whether the two vertices a and b are connected.
a = find(a);
b = find(b);
return a == b;
}c
int size_component(int a) {c
// Find the size of a particular component.
// Question: Why do we need to call `find`?
return size[find(a)];
}c
int num_components() { return n; }
};
Complexity Analysis
And that is all the changes required to reduce the complexity of union find, but how much has it done?
Well, to construct a rank 2 tree we need to merge 2 rank 1 trees, to construct a rank 3 tree we need to merge 2 rank 2 trees, and so on and so forth. Therefore in a union find with n vertices, we have at most log2(n) rank on each tree in our data structure.
This means that find is log(n), meaning both merge and connected are also log(n). (In fact, with the path compression above, the complexity is even less (inverse ackermann), but this isn’t super important under contest conditions)
And that’s the data structure fully taken care of. Now let’s solve some problems!
A simple application
Let’s try our hand at Friend Circle. Give it a shot yourself before reading the discussion below!
(Note: The time bounds for this problem are very small. Python will probably TLE. But give it a shot anyways!).
Hint
While the problem description is a bit sparse, hopefully you can spot that we care about what group of friends are connected by some friendship (If A and B are friends, and B and C are friends, then all 3 form a circle of friends, no need for A and C to be friends.)
So, if we let every person be a vertex in our graph, with edges representing friendship, then Union Find is exactly the tool we need. Before we get into coding we need only ask ourselves two things:
- What is the maximum size of our Union Find
n? - How will I turn people’s names into the digits
0ton-1?
Solution
To answer 1, the maximum number of people is simply 2 times the total number of connections. For 2, we can use a dictionary/map to map strings to integers. To ensure every person is unique from 0 to n-1, we can start a counter at 0, and every time we see a new name, increment this counter. Then the old value of the counter is the id for that person:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from collections import defaultdict
t = int(input())
for _ in range(t):
connections = int(input())
max_people = 2 * connectionsb
uf = UnionFind(max_people)b
cur_counter = 0
def count_increase():
global cur_counter
cur_counter += 1
return cur_counter - 1
# The defaultdict now assigns a new id to every new person mentioned.
person_map = defaultdict(count_increase)
for _ in range(connections):
p1, p2 = input().split()
uf.merge(person_map[p1], person_map[p2])b
print(uf.size_component(person_map[p1]))b
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
int main() {
int tests;
int connections;
cin >> tests;
for (int t_no=0; t_no<tests; t_no++) {
cin >> connections;
int max_people = connections * 2;b
UnionFind uf(max_people);b
int counter = 0;
map<str, int> person_map;
for (int c=0; c<connections; c++>) {
string c1, c2;
cin >> c1 >> c2;
if (person_map.count(c1) == 0) person_map[c1] = counter++;
if (person_map.count(c2) == 0) person_map[c2] = counter++;
uf.merge(person_map[c1], person_map[c2]);b
cout << uf.size_component(person_map[c1]) << endl;b
}
}
return 0;
}
A slightly hidden application
Next, lets try a harder problem - Roads of NITT.
Have a go!
(Note: The input format is very weird (There’s some whitespace where there shouldn’t be). My current python solution fails for this reason)
Hint
This problem seems similar but different to the problem above. We are still asking about connectivity, but we are breaking connections rather than forming them :(.
Consider this though - Would you be able to solve the problem if it was told in reverse?
Solution
Looking at the problem in reverse, it seems we start off with a disconnected area, and then bit by bit, more connections are made. This is starting to look like Union Find!
So all we need to do is:
- Calculate what roads remain at the end of the problem
- Answer the queries in reverse, joining instead of destroying
- Reverse these results and print them
However, we need to be a bit careful about what our results are in the first place - We want to count how many pairs of hostels are disconnected - This is an N^2 operation. We can do this in N using union find (For every vertex, we know how many vertices it is connected to (and therefore not connected to)), but we still don’t want to do this for every query. Let’s start by calculating the correct value after all roads have been destroyed.
If a road is formed, how many old pairs of hostels are no longer disconnected? A hostel can only be connected now and disconnected before if one of the hostels was already connected to the LHS of the road, and the other hostel was already connected to the RHS of the road. The number of possible pairs here is the size of the component on the LHS of the road, times the size of the component on the RHS of the road.
So every time we see an R query, we just need to update our current count of disconnect pairs using the Union Find:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
t = int(input())
for _ in range(t):
n = int(input())
edges = []
for _ in range(n-1):
x, y = list(map(int, input().split()))
# 0-index
edges.append((x-1, y-1))
connected = [False] * len(edges)
q = int(input())
queries = []
for _ in range(q):
queries.append(input())
if queries[-1].startswith("R"):
connected[int(queries[-1].split()[1])-1] = False
uf = UnionFind(n)b
# Add all remaining roadsb
for a in range(len(edges)):b
if connected[a]:b
uf.merge(edges[a][0], edges[a][1])b
# First - calculate how many pairs of hostels are disconnected.
current = 0b
for x in range(n):b
current += n - uf.size_component(x)b
current //= 2b
# Answering time!
queries.reverse()
answers = []
for q in queries:
if q.startswith("Q"):
answers.append(current)
else:
edge_index = int(q.split()[1])-1
current -= uf.size_component(edges[edge_index][0]) * uf.size_component(edges[edge_index][1])b
uf.merge(*edges[edge_index])b
answers.reverse()
for a in answers:
print(a)
# Separate ouput by a space
print()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
vector<pair<int, int> > edges;
vector<bool> connected;
vector<int> queries;
vector<int> answers;
int main() {
int tests;
cin >> tests;
for (int t=0; t<tests; t++) {
edges.clear();
connected.clear();
queries.clear();
answers.clear();
int n;
cin >> n;
for (int i=0; i<n-1; i++) {
int x, y;
cin >> x >> y;
// 0-index
edges.push_back({x-1, y-1});
}
connected.assign(n-1, true);
int q;
cin >> q;
for (int i=0; i<q; i++) {
string s;
cin >> s;
if (s == "Q") {
queries.push_back(-1);
} else {
int a;
cin >> a;
queries.push_back(a-1);
connected[a-1] = false;
}
}
UnionFind uf(n);
// Add all remaining roads
for (int i=0; i<n-1; i++) {b
if (connected[i]) {b
uf.merge(edges[i].first, edges[i].second);b
}b
}b
// First - calculate how many pairs of hostels are disconnected.
int current = 0;b
for (int i=0; i<n; i++)b
current += n - uf.size_component(i);b
current = current / 2;b
// Answering Time!
reverse(queries.begin(), queries.end());
for (auto qn: queries) {
if (qn == -1) {
answers.push_back(current);
} else {
current = current - uf.size_component(edges[qn].first) * uf.size_component(edges[qn].second);b
uf.merge(edges[qn].first, edges[qn].second);b
}
}
reverse(answers.begin(), answers.end());
for (auto a: answers) {
cout << a << endl;
}
cout << endl;
}
return 0;
}